![telc Deutsch B1 [Part - 1]](/content/images/size/w300/2026/02/telc_b1_prep_part1.jpg)



Introduction to Mysql Internals
In this article, we will talk about high-level database internals, specifically MySql's that already overlaps with many other databases. We will talk about architecture, concurrency, transactions, ACID, Deadlocks, and MVCC

•

In this article, we will talk about high-level database internals, specifically MySql’s that already overlaps with many other databases.
We will talk about architecture, concurrency, transactions, ACID, Deadlocks, and MVCC
What is a database
A database is an organized collection of data stored and accessed electronically from a computer. A database is controlled by a database management system known as DBMS. The data, the DBMS, and the applications associated with them are called a database.
MySql architecture
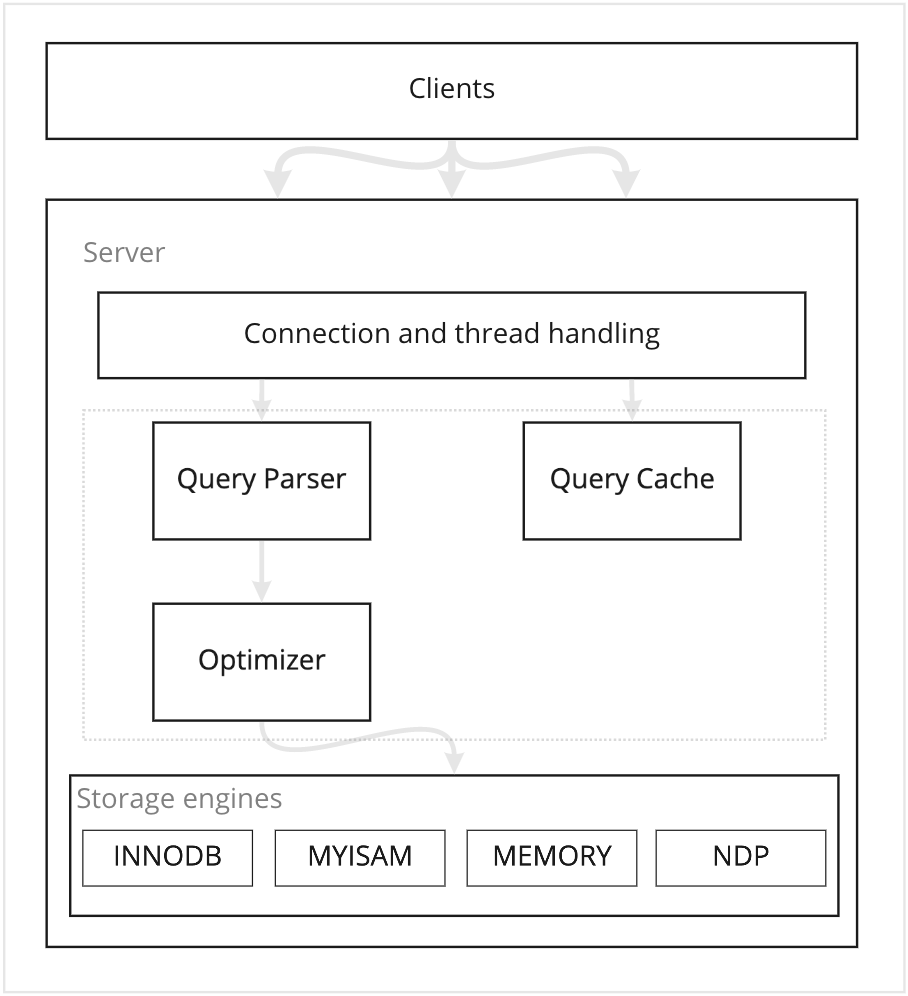
Connections and threads handling
This layer handles network connections, authentication, security, and more. The default thread-handling model in MySQL Server executes statements using one thread per client connection, and this will lead to performance degradation when more connections are received. There are thread pool plugins that can be used to increase the server performance, by leveraging the multi-core systems.
Query parser, cache, optimizer
At this level, most work of MySQL happens. When a query got executed, MySQL checks if the query is cached to return it, or else it will parse, optimize, execute and cache the results. The parser will parse the query into a parse-tree data structure and then optimize it. Optimization can be in deciding which index should be used with the query, and it tries to use the most restrictive index so it eliminates more rows earlier. Also, it eliminates dead codes, like when a condition is always true or always false
Storage engines
Storage engines are the components responsible for storing and retrieving data. Every engine has its own characteristics that should be used in order to know which engine should you use for your data.
Concerency
Concurrency is when multiple readers and writers try to read or/and write at the same time. When multiple processes are writing on the same piece of data, this can lead to an inconsistent state. To solve this problem we may lock that piece of data from being modified if someone else is already modifying it.
Locks
Locks help to make the data more concurrent friendly. When working with shared data and many processes are writing/reading that data we can restrict access to that data while it is being changed to protect it from being corrupt.
There are two kinds of locks in MySQL Shared lock: This is explicitly requested (for example, SELECT ... LOCK IN SHARE MODE) when you need a locking read. InnoDB serves regular SELECT queries through MVCC snapshots without taking shared locks, so concurrent readers do not block each other. Exclusive lock: This is used when updating or deleting data from MySQL. This lock depending on the used isolation level, it may not allow any other transaction to write/read the locked record.
Lock granularity
Lock granularity is defined by the range of the data we are locking and it can be table or row lock. And every one of them is a tradeoff between concurrency and overhead.
Table locks
This kind of lock is when a whole table is being locked. It is a very basic type of locking that has the lowest overhead
Row locks
This kind of lock is only concerned about the row level, so it will lock a row or multiple rows for reading or writing. Mysql will use the index available to decide what rows to lock. Auto-inc locks: This is a special table-level lock that occurs when inserting in a table with AUTO_INCREMENT columns.
There are many kinds of row locks: Record-locks: This is when locking a record based on an index, and if the table has no index InnoDB will define a hidden clustered index and it will use it to lock the records Gap locks: This is when locking a gap between index records. Like it will disallow us from inserting 5 when we have SELECT x FROM t WHERE x BETWEEN 1 and 10 FOR UPDATE; transaction in process.
Locking strategies differ from a storage engine to another, so try to have an overview of what every engine offers and based on it decide which engine you should use.
Transactions
A transaction in MySQL is a set of queries that define a single unit of work, so either all applied or none applied. That means if a transaction has 4 queries, all 4 queries should be applied, and if one failed the other should be rolled back as if they were not applied in the first place.
A database system must meet ACID properties. ACID properties are strongly tied to the transactional system in the DB.
Atomicity
A transaction should represent an atomic unit of work. When a transaction does multiple changes to the DB, either all changes are applied on success or all rolled back on any failure.
Consistency
Data in the database remains in a consistent state all the time. If any related data is being changed across multiple tables, all queries should either see old values or new values, never a mix between old and new.
Isolation
Based on isolation levels, transactions should be protected from each other while they are not committed. They should not interfere with each other and should not see their uncommitted data.
Durability
When a transaction is committed and succeeded, its changes should be persisted and safe from any kind of external failure.
Isolation levels
Isolation level is the I in ACID and it differs from a storage engine to another. Every level is a tradeoff between reliability, consistency, and reproducibility of the results in a concurrent system.
READ_UNCOMMITTED
This provides the least amount of consistency and data protection. but it has the least overhead as well. This isolation level allows other transactions to access results of uncommitted transactions which are also known as Dirty reads. This kind of isolation level should be used with caution, and you should really know what are you doing in order to use it.
READ_COMMITTED
This level is the simplest form of isolation and it means that a transaction can only access results from other transactions only if they are already committed. This transaction level is the default in many database systems, but it allows unrepeatable reads, which means in the same transaction if you read the same row at the beginning and at the end, and another transaction committed a change to this row after your first read, the second read will get different information in that row. basically, it is when a row is retrieved twice and the values within the row differ between reads.
UNREPEATABLE READS is because of an update statement
REPEATABLE_READS
This isolation level solves the unrepeatable read problem by locking any subsequent reads for the same data in the same transaction, this will guarantee that if the transaction reads the same data multiple times it will get the same results. This level is the default in MySQL, but also it allows phantom reads which is in the same transaction when executing two identical queries you will get different set of rows
PHANTOM READS is because of an insert statement
SERIALIZABLE
This is the highest level of isolation and it uses the most conservative locking strategy to prevent any other transactions from inserting or changing data that was read by this transaction until it is finished. Basically, it places a lock on every row it reads.
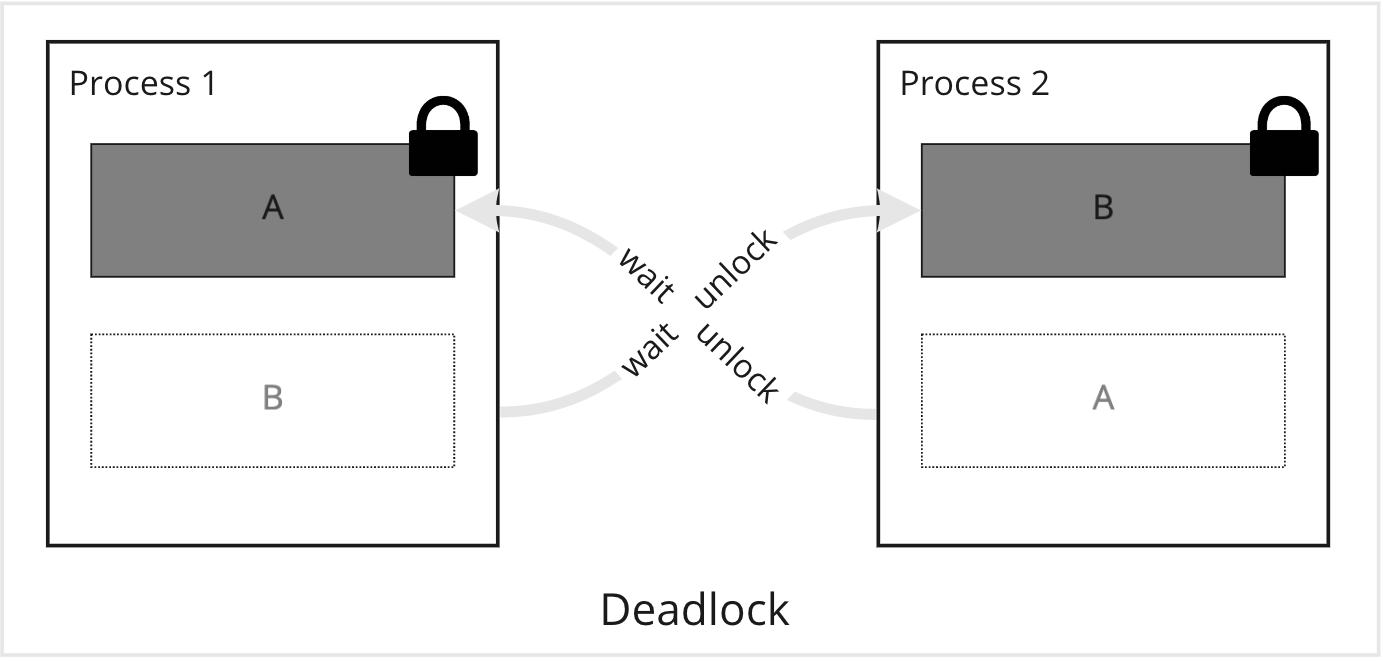
Deadlock
A deadlock occurs when two transactions are waiting for each other to release a lock on the same resources.
Multi-version concurrency control (MVCC)
MVCC in MySQL is used to increase concurrency by only locking necessary rows during write operations. Simply it keeps a snapshot of the old version of the data at a point in time to allow a transaction to see a consistent view of the data. Every engine implements MVCC in a different way, but all use versioning to maintain a consistent view of data during the transaction lifetime. MVCC is only available with REPEATABLE_READS and READ_COMMITTED isolation levels.
MVCC with a SELECT transaction
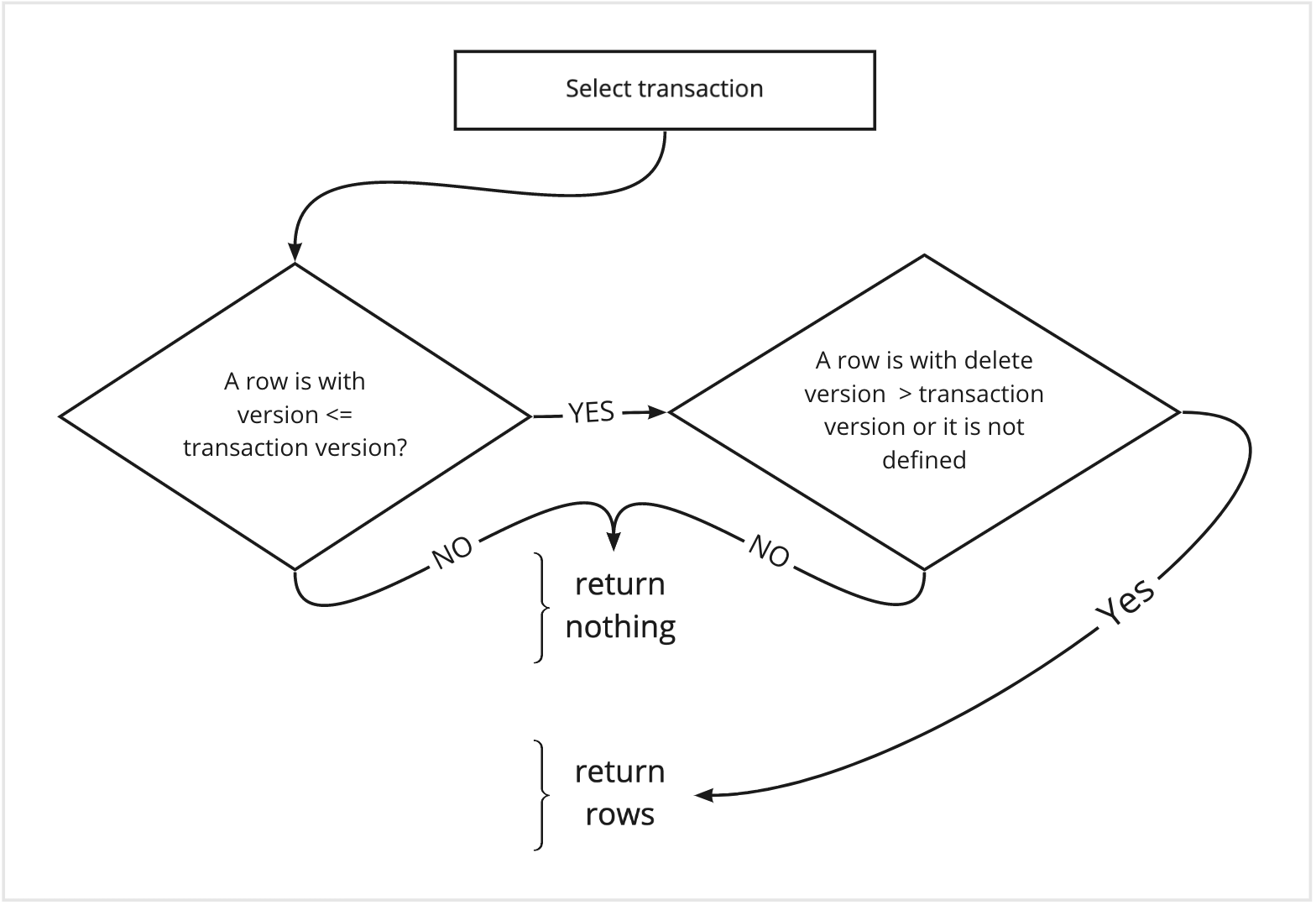
MVCC with INSERT
The DB engine will record the current system version number with the new row.
MVCC with DELETE
The DB engine will update the row delete version with the current system version number.
MVCC with UPDATE
The DB engine will write a new copy of the row with the current system version number and update the old row deletion version with the current system version.
Join the discussion
Comments