


What The Heck is HTTP
HTTP is a protocol that we can connect a client and a server and exchange messages between them. And This communication happens in the form of request/response. A request is a message we send from the client to the server, and the response is the reply from the server to the client.

•

What is HTTP?
Hyper Text Transfer Protocol is a protocol or, in other words, a set of rules that defines how two computers should communicate. And it allows a client to fetch resources from a server. The resources can be any digital file like HTML file, audio, video, and so on.
As any two communicators, client and server communicate by exchanging messages over the TCP or TLS encrypted TCP. Note that HTTP can be implemented on top of any protocol other than TCP unless it does not guarantee reliable transport. And The HTTP protocol is simple, and it uses plain text in communication except for HTTP/2.
Request
A request is a message that a client sends to the server.
Response
A response is a message that the server sends to the client.
Client <-> Server
Client and server are the main components of HTTP in addition to the Proxy. A client will send a request to the server. Before the request hits the server, it might be pass through multiple proxies. When the request reaches the server, it will process it and send back a response passed through various proxies and devices such as routers and modems before it gets to the client.
A proxy server is an intermediate program or computer used when navigating through different Internet networks.
HTTP charactaristics
- HTTP is stateless
- HTTP is extensible
- HTTP is reliable
Stateless
Stateless means that HTTP requests from one client to a server are not related in any way, even if they are sent on the same connection.
Even though HTTP is fully stateless, the HTTP cookies can be used to have a stateful session and allow requests to share the same state every time.
HTTP is extensible
HTTP is designed in a way that is easy to extend thanks to the concept of the header. New functionality can be as simple as an agreement between the client and the server over the headers semantics. The cookies are one example of HTTP extensibility in addition to Cache, Authentication, and CORS constraints.
HTTP is reliable
The main requirement for the protocol to be used in HTTP is to be reliable, and by reliable, it means that it cannot lose messages or at least it presents an error in such a case.
Reliability is behind that HTTP is implemented on top of TCP and not UDP.
HTTP flow
When a client wants to communicate with a server, these steps will happen:
- The client opens or reuses a TCP connection to send one or more requests and to receive responses as well
- The client sends an HTTP message
- Receive the response from the server
Uniform Resource Identifier (URI)
URI is a unique identifier that represents an address of a resource on the internet. Using URIs, we can get resources over the internet, like images, movies, or even web pages.
URI comes into two specialties, URL and URN.
Uniform Resource Locator (RUL)
URL is a widely used form of URI, and like URI, URL identifies the address of the resource. But in addition, it also specifies how that resource should be retrieved.
URL Components
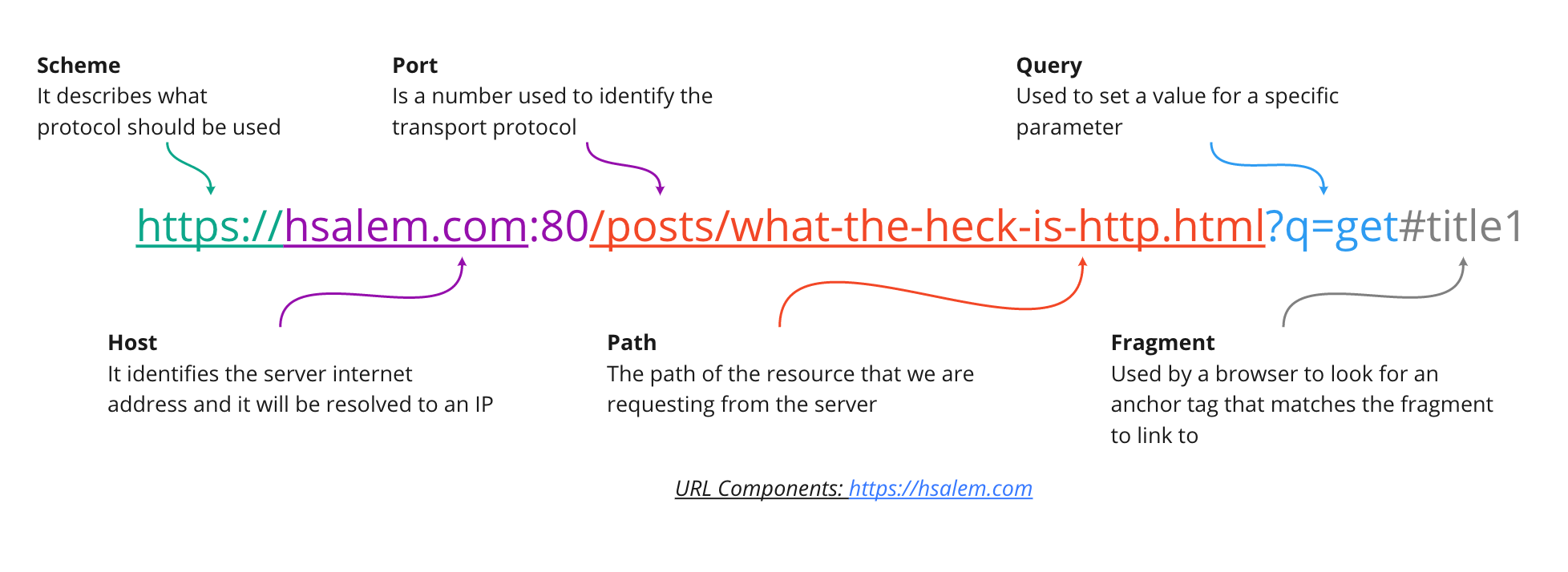
Uniform Resource Name (URN)
URN is also used as an address, but it is location-independent. So URN is more of a “globally” unique name of a resource, and it can be used to access that resource no matter where it exists currently and whether it is being moved or not.
URN Components

HTTP communication
HTTP is a protocol that we can connect a client and a server and exchange messages between them. And This communication happens in the form of request/response. A request is a message we send from the client to the server, and the response is the reply from the server to the client. These HTTP messages are special data blocks that have the required information for a specific HTTP call.
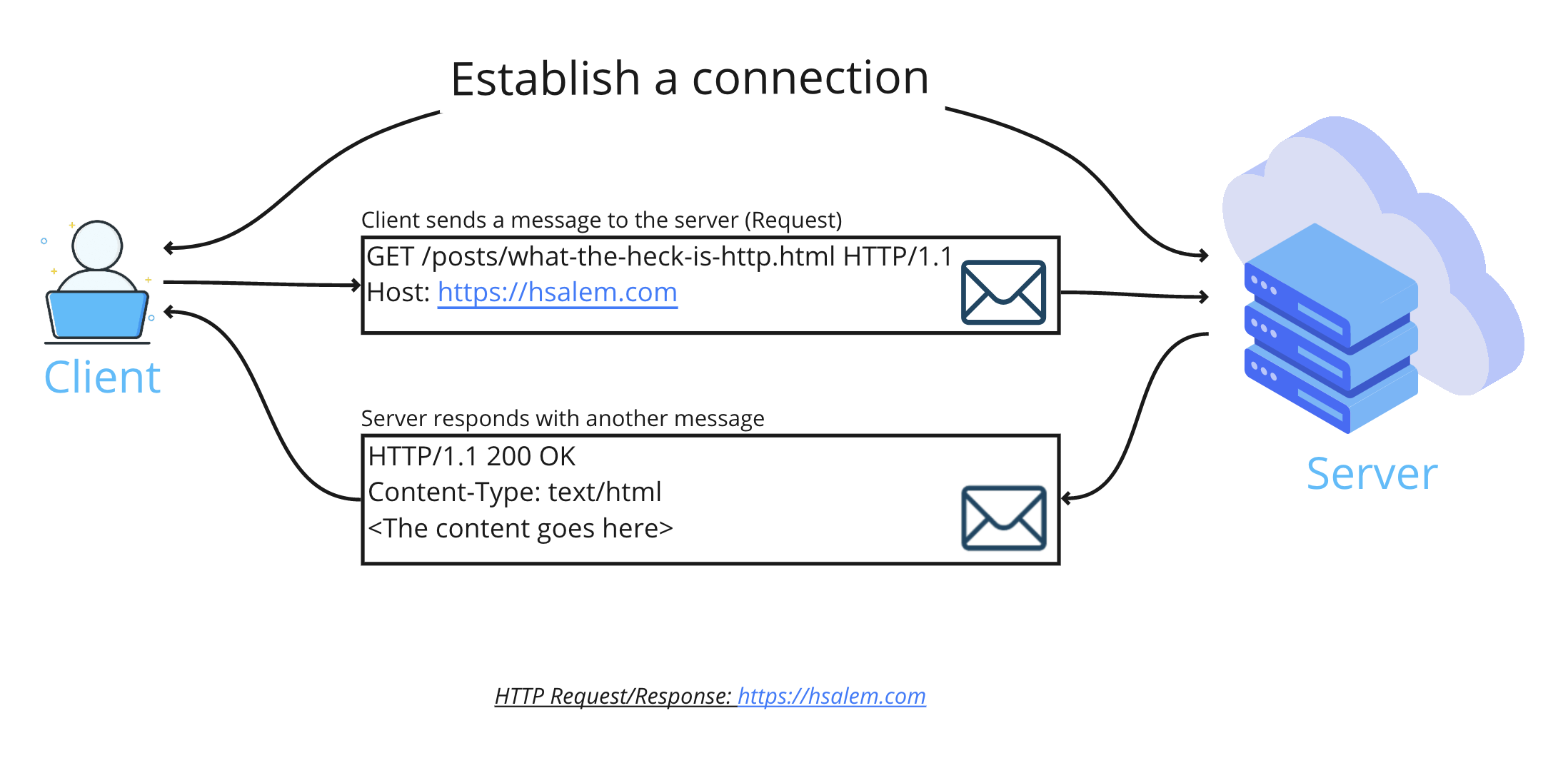
The previous diagram shows a basic HTTP request/response operation that a client initiates. The client initiates a connection to a server. The client sends a request message to the server. The message contains all the needed information about the client and the requested resource. The server handles this message then it responds with a response message.
Both these messages have a particular format and may include optional headers and/or a body. The body is separated from the headers by an empty line.
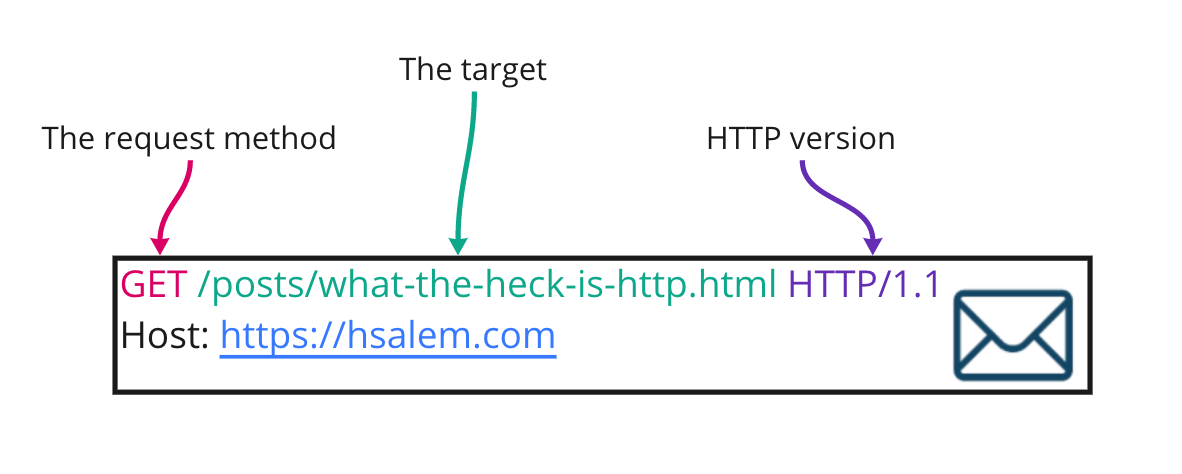
We start with the verb GET on the request message, which is a special keyword and is called the request method. There are more verbs than GET, like: PUT, POST, DELETE, LINK, UNLINK, and HEAD. Every verb can be used in a particular use-case.
Then the target, which is the path for the requested resource. The target can be either a URL or an absolute path.
Then the HTTP version, the version defines the structure of the rest of the message.
HTTP methods
GET: Is used to retrieve information from the serverPUT: Used to update or create an entityPOST: Used to process data, like login data or add a record in the database.DELETE: Used to delete the resource that is represented by the request URILINK: Used to establish a link relationship between one or more resources that are identified by the request URIUNLINK: Used to remove the link relationships between resourcesHEAD: Used to get metainformation about the resource identified by request URI, and it does not fetch the resource itself.
Join the discussion
Comments